Always-on production Flame Graphs for Java - now with thread grouping
 Sadiq Jaffer
&
Sadiq Jaffer
&
 Richard Warburton
Richard Warburton
Today we’re going to be introducing Opsian’s always-on production Flame Graphs for Java. Flame Graphs are a state-of-the-art visualisation that can help you rapidly identify bottlenecks and hot paths from profiling information. In this post we will cover some of the basics on what Flame Graphs are, how to use them effectively and then look at some real production examples.
What are Flame Graphs?
Before we get ahead of ourselves, let’s briefly go over what a Flame Graph is and how it can be used for those who might not be familiar.
With Opsian, our agent samples the threads in your application periodically and we get snapshots of their current state as a stack trace, like so:
| java.lang.Thread.run:748 |
| java.util.concurrent.ThreadPoolExecutor$Worker.run:624 |
| java.util.concurrent.ThreadPoolExecutor.runWorker:1149 |
| com.yourapplication.YourClass.workerMethod:42 |
| com.yourapplication.YourClass.anotherMethod:121 |
Here the thread that was sampled was currently in the anotherMethod() method, which was called by workerMethod and so on.
Popularised by Brendan Gregg, Flame Graphs offer a way of visualising a set of stack traces in a form that makes it easier to identify hot code paths and bottlenecks.
Flame Graphs transform a collection of these stack samples into an aggregated form. For simplicity’s sake assume we have a three types of stack samples and have 33 of each:
| A.a() |
| B.b() |
| C.c() |
| A.a() |
| B.b() |
| D.d() |
| A.a() |
| E.e() |
| C.c() |
These samples get aggregated in to the following:
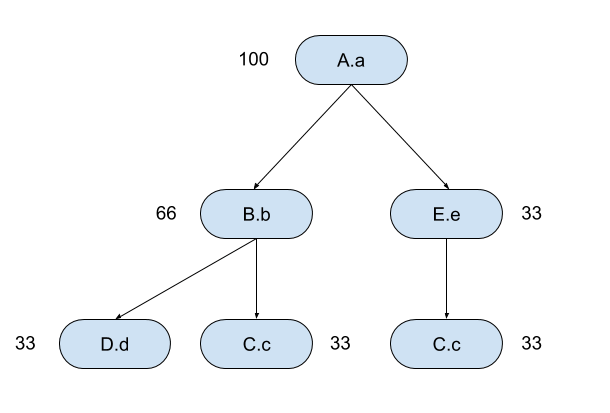
To render this in to the final visualised form we start at the root and this represents the first box on our graph, taking up 100% of the horizontal width.
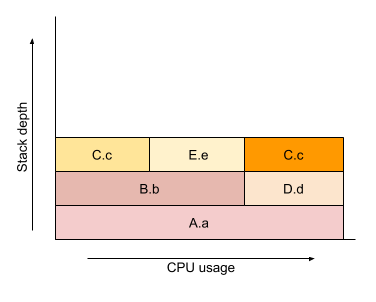
We then walk down the tree rendering each level vertically with width proportional to the number of samples we have at that node.
One slightly complicating factor is that of self time vs total time. Self time refers to the amount of time spent executing the function itself, rather than calling any other functions. Total time is the time spent executing the function and any functions it calls.
In the context of stack samples, we saw in the original stack sample that the thread was executing somewhere inside the anotherMethod method at the time the sample was taken. This would increment the self time and total time for that method, whereas all the other methods (workerMethod, runWorker and run) would only have their total time incremented.
Let’s replace the simple Flame Graph above with one that better reflects self and total time.
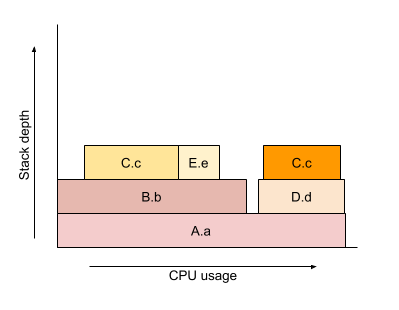
To read a Flame Graph like the above, start at the bottom. We can see that all samples involve method A.a() which has the full horizontal width as it appears in 100% of samples. Above it are B.b() and D.d(), though they don’t occupy the full width between them. The width they don’t occupy is A’s self time, which is relatively small compared to its total time. This probably means A isn’t a good candidate for optimisation, since it may be doing relatively little.
Next we have B.b(), which calls C.c() and E.e(). B.b()’s self time is a considerable percentage of its total time and might be an opportunity for optimisation. More of an opportunity might be C.c() however, which appears twice in the Flame Graph and which is all self time.
Opsian Flame Graphs
Let’s take a look at a real Flame Graph from Opsian:

This Flame Graph is from data gathered from one of our frontend Collector instances that gathers profiling data sent from agents and then fans it out to the rest of our system.
Another real example is from part of our system used for rolling up samples in to aggregations.

Here we can quite clearly see that calculating the rolling checksums takes approximately 35% of our CPU time while we’re decompressing through a batch of stored samples. The actual decompression and message deserialization take 48% and 9% respectively.
Thread Grouping
Opsian’s Flame Graphs support aggregating samples from your entire application or just individual thread groups:
This is useful if the application being monitored has groups of threads that have very different functionality and performance profiles.
Analysis dimensions
Opsian’s agent attaches contextual information to the sampled stack traces, such as the current version of your application, your identifier for the agent, host name and, runtime environment. Through the reporting UI, Flame Graphs can be generated for any combination of the available dimensions, allowing you to analyse performance across application versions or even individual hosts:

Limitations of Flame Graphs
While Flame Graphs are a great way of visualising a collection of profiling information they do have limitations. As we saw in the very first example where C.c() was called by both B.b() and D.d(), it can be hard to spot hot pieces of code that are called from many different parts of the codebase.
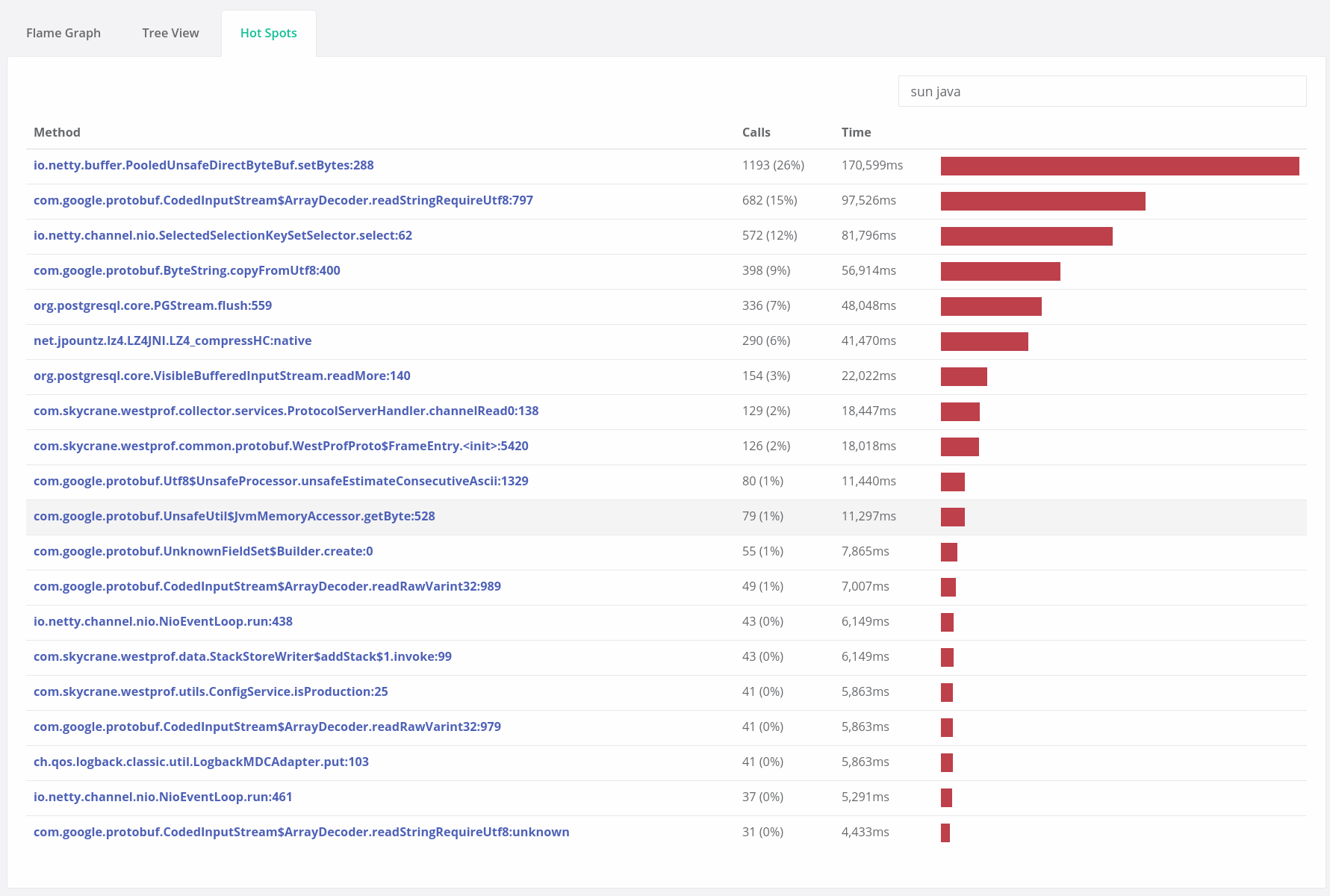
To address this, Opsian offers two other types of visualisations. Hot Spots, which identifies hot methods regardless of where they are called from and can surface things that might be missed on a Flame Graph:
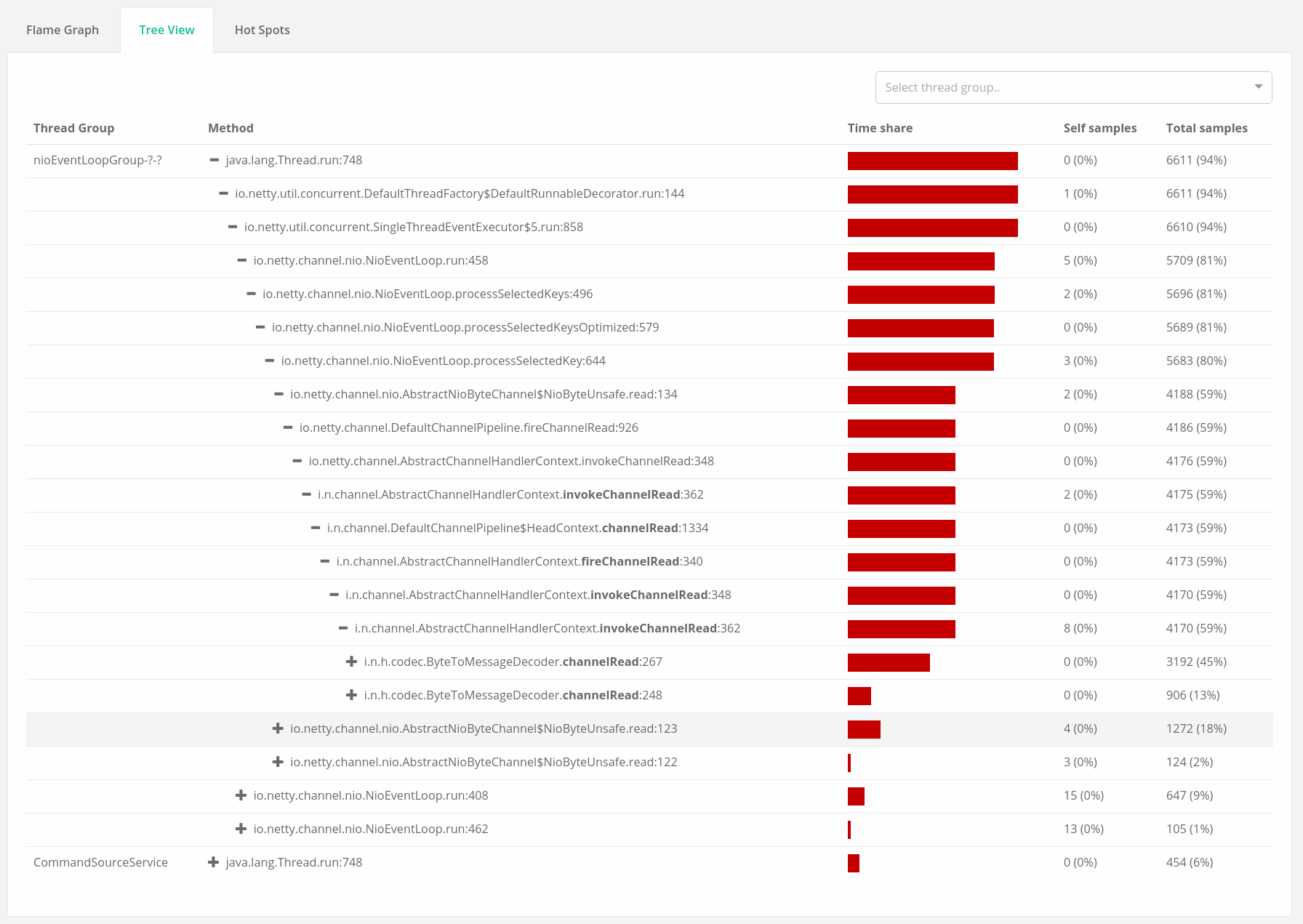
Additionally there are Tree Views, which enable you to take a top-down view of your code and drill down through the call hierarchy. This can be useful for exploring particular code paths with line-level granularity:
Flame Graphs enable you to visualise performance profiling information in a way that can quickly identify hot codepaths and bottlenecks in your code.